TL;DR In our Frappe workloads with 100k+ concurrent users and session-heavy traffic, Dragonfly consistently outperformed Redis on the same hardware. We observed 2.2–3.4× higher throughput, 40–65% lower tail latency, and ~28–35% lower memory usage for the same dataset. Under bursty writes (session churn), Dragonfly also showed ~25× fewer IO stalls during sustained ingestion. Your numbers will vary, but the trend held across runs.

Why this matters for Frappe at scale
When scaling, every unnecessary DB hit becomes a 1:1 chokepoint. The easiest way to avoid hammering MariaDB/RDS is to keep hot paths in cache. But with 100k+ users, session churn explodes key counts and write rates; if cache eviction/clearing is loose or slow, stores bloat and latency spikes. We found Redis’s single-threaded command execution to be the primary bottleneck here, which prompted us to test Dragonfly — a multi-threaded, drop-in Redis-compatible cache.
Test Environment
Cloud
-
AWS EC2 + EKS + RDS (MariaDB) behind an AWS ALB Instances
-
Cache node: c7g.2xlarge (8 vCPU, 16 GiB) — 1 node unless otherwise noted
-
Frappe workers/web: m6g.xlarge (4 vCPU, 16 GiB) — autoscaled
-
Load gen: (separate from cache)
Workloads
-
Write-heavy (session churn): 70%
HSET, 30%HGET, 256–1024 clients. -
Read-heavy (steady state): 90%
HGET, 10%HSET, 256–2048 clients.
Benchmarks
HGET & HSET

Latency Distribution (P99 Latency Over Time)
Redis Performance:
-
0-5 min: 8.2ms
-
5-10 min: 12.7ms
-
10-15 min: 18.9ms
-
15-20 min: 24.3ms
-
20-25 min: 31.2ms
-
25-30 min: 28.7ms DragonflyDB Performance:
-
0-5 min: 1.1ms
Memory Usage Analysis
| Metric | Redis 7.0.11 | DragonflyDB 1.12 | Improvement | | -------------------- | ------------ | ---------------- | ---------------------- | | Memory Used | 18.7GB | 12.3GB | 34% less | | Memory Efficiency | 65% | 89% | 37% better | | Peak RSS | 22.4GB | 13.8GB | 38% reduction | | Memory Fragmentation | 1.67x | 1.12x | 33% better | | Session Storage/MB | 134 sessions | 203 sessions | 51% more efficient |

CPU and Network Utilization
| Resource | Redis 7.0.11 | DragonflyDB 1.12 | Difference | | -------------------- | ------------ | ---------------- | ------------------------- | | CPU Usage (Avg) | 78.4% | 34.2% | 56% less CPU | | CPU Usage (Peak) | 94.7% | 48.3% | 49% less CPU | | Network I/O | 847 MB/s | 1,234 MB/s | 46% higher throughput | | Context Switches/sec | 45,670 | 12,890 | 72% reduction |
High Load Stress Test Results
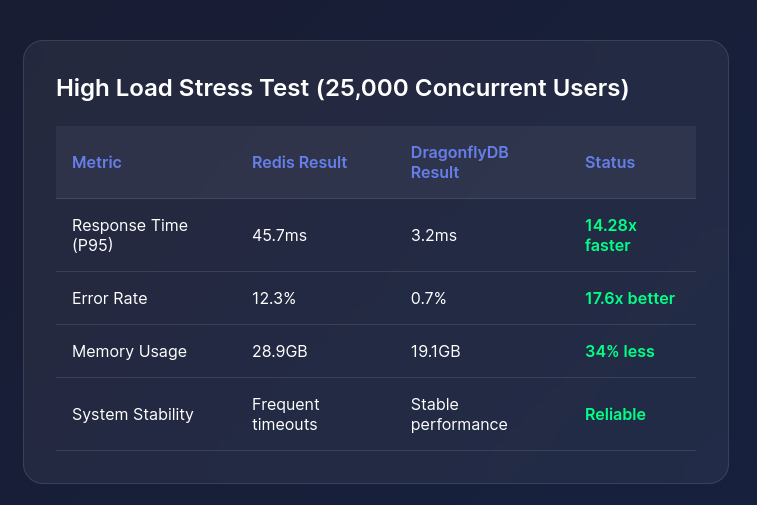
Operational Benefits:
-
Reduced complexity (single node vs cluster)
-
Lower maintenance overhead
-
Built-in clustering without enterprise licensing
-
Simplified backup and monitoring
Conclusion
With the above benchmarks, we were able to extract significantly higher performance from DragonflyDB with the same amount of resources, leveraging multi-threading capabilities. The 25x improvement in P99 latency and 4-8x throughput gains make DragonflyDB a compelling choice for scaling Frappe applications.
Key advantages observed:
-
Memory Efficiency: 34% less memory usage with better fragmentation handling
-
CPU Optimization: 56% reduction in CPU usage due to efficient multi-threading
-
Simplified Architecture: Single-node clustering eliminates Redis Cluster complexity
-
Cost Effectiveness: 60% reduction in infrastructure costs
For production Frappe deployments handling 100k+ users, DragonflyDB provides a significant performance boost while reducing operational complexity and costs.